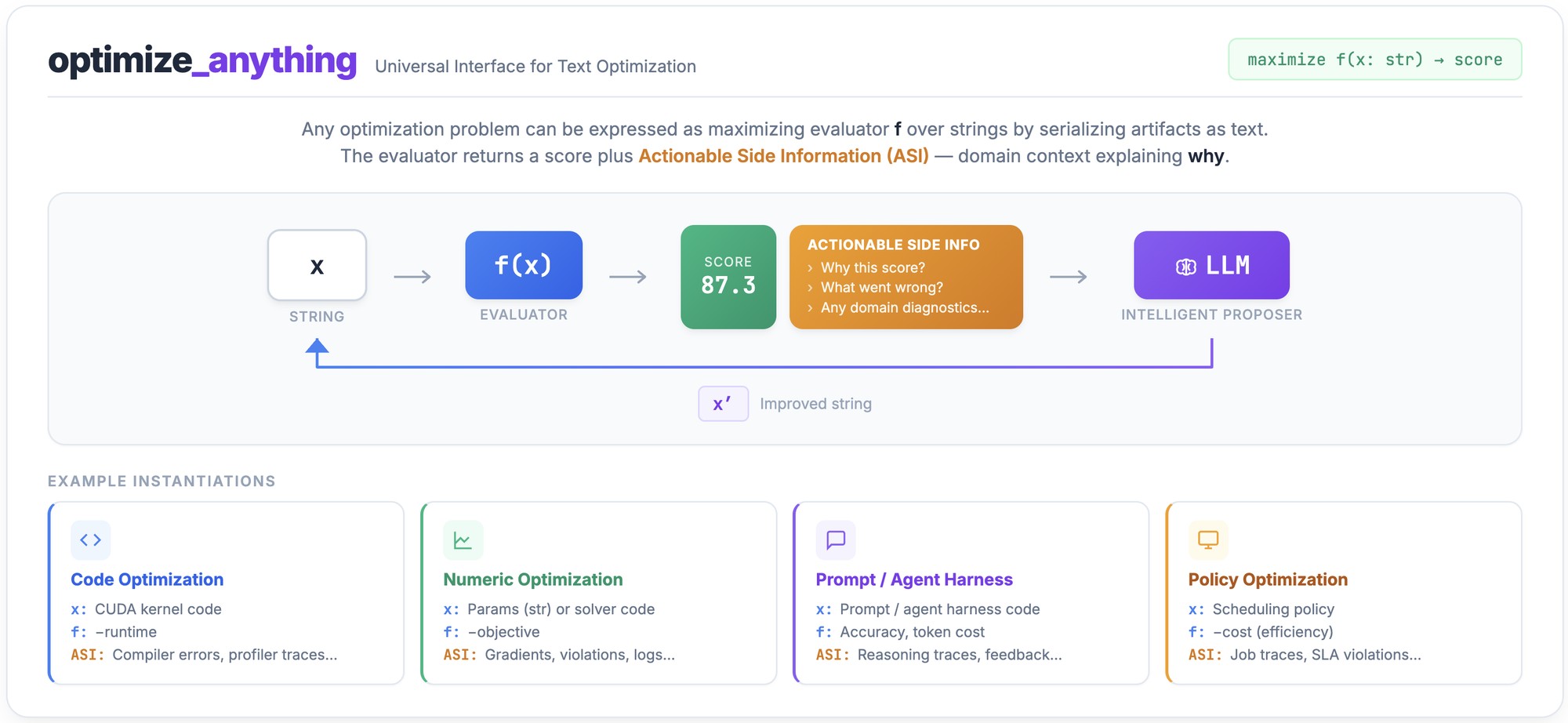
自改进 Agent 全景综述:从 Good 的终局发明到 Schmidhuber 的自指涉学习
KAUST / Jilin / IDSIA 联合出品,Schmidhuber 署名。97 页综述统一自改进 Agent 框架 A_t = (θ_t, Σ_t):参数改得慢但深,脚手架改得快但浅,好的系统双层并跑分层收敛。覆盖 200+ 篇论文,从 1790 年 Laplace 一路梳理到 2026 ...
Read MoreSchema:一个让 AI 像物理学家一样思考的 Harness
Schema 不改变模型权重,而是改变模型周围的过程——让 AI 像物理学家一样从原始像素中构建可编程的世界模型。ARC-AGI-3 Public 集 RHAE 98.98%,固定模型仅换 harness 提升 +56pp。...
Read More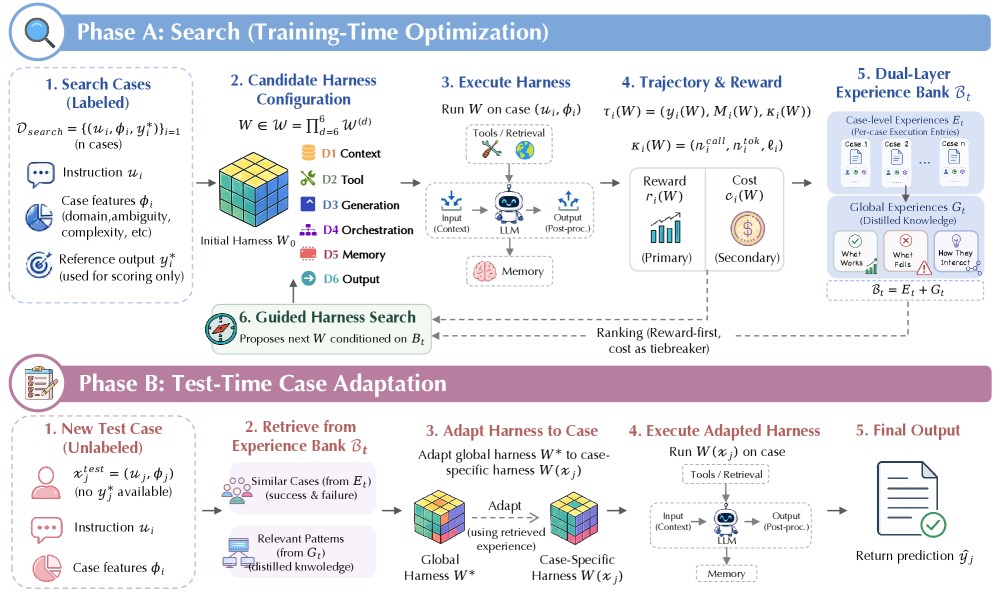
Agent 的"操作系统"也需要学习:MemoHarness 把执行经验变成可复用的控制层
Notre Dame / LMU Munich / USC 提出 MemoHarness:agent harness 不应手写,而应从执行经验中学习。六维 harness 空间 + 双层经验银行 + 测试时无标签适应,Terminal-Bench 达 0.806,超越所有固定 harness 基线,...
Read More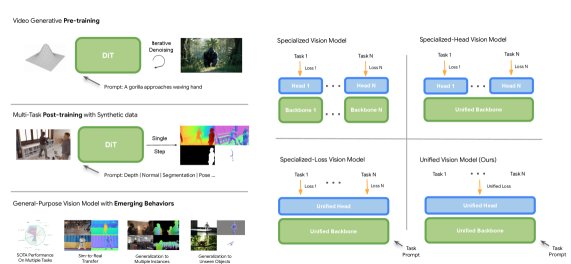
GenCeption:视频生成模型的真正使命——通用视觉智能
Google DeepMind提出视觉基础模型第三条道路:文本到视频生成预训练同时覆盖空间-时间-语言三维度,扩散backbone改造为单步前馈感知模型,3B规模匹配DepthAnything V3/SAM3/VGGT-Ω等专用SOTA,训练数据少7-500倍;纯合成人体视频训练即可zero-sho...
Read More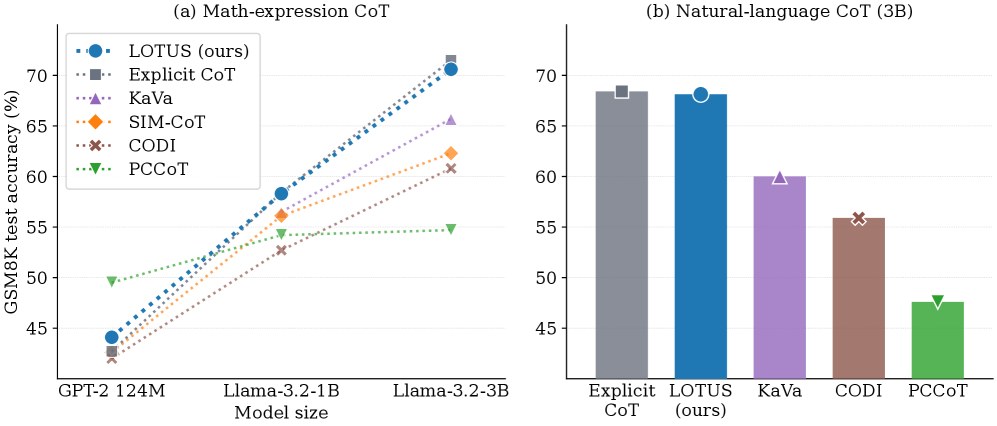
LOTUS:用循环Transformer弥合隐式推理与显式推理的鸿沟
Microsoft Research联合ETH提出LOTUS:循环backbone并行打磨隐向量破解序列生成瓶颈,gold CoT token直接交叉熵监督破解对齐信号缺失——隐式推理首次在3B规模匹配显式CoT准确率,推理快2.5-6.9倍;隐空间可被LM head直接解码出推理步骤,还编码了训练...
Read More
持续学习到底什么时候需要"真学习"?
UC Berkeley统一评测八种持续学习方法,证明没有银弹——真正的分水岭在于任务需要"改prompt就够了"还是"必须学进权重":上下文可容纳的知识用检索/prompt方案更稳,超出上下文或需要技能内化时参数更新不可替代。...
Read More
大模型需要"睡觉":从人类记忆巩固机制到LLM持续学习新范式
LLM有和人类顺行性遗忘症相似的缺陷——只有短期记忆(上下文)和凝固的长期记忆(预训练参数),中间没有巩固机制。Google Research提出"睡眠"范式:NREM式记忆巩固(参数扩展+向上蒸馏+突触修剪)+ REM式做梦(自生成合成数据+MoE混合知识域)。Qwen3-8B上AIME-24达7...
Read More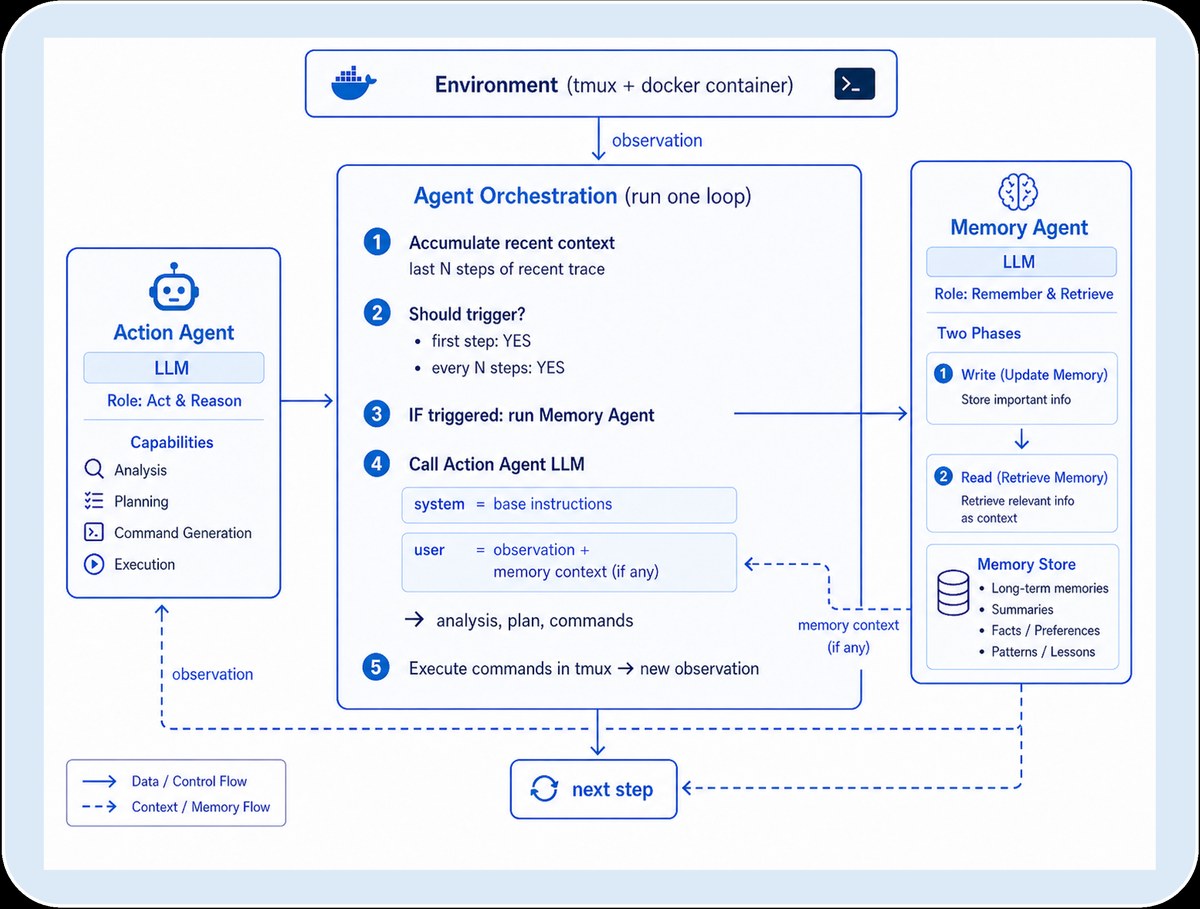
Agent的"健忘症"该怎么治?Meta提出主动记忆Agent,让长程任务不再丢状态
Meta提出Proactive Memory框架——Agent在推理间隙自动执行记忆维护(记忆选择→检索→更新→写入),用元学习训练记忆策略网络替代规则型memory模块。AiderHumanEval 94.4%完成率、ALFWorld 95%成功率、WebArena 60.9%,全面超越ReAct...
Read More
LLM-as-a-Verifier:把验证本身变成可扩展的新轴
验证和生成一样,是可以被系统化扩展的维度。从离散 argmax 分数换成 logprob 分布期望,三个扩展轴(粒度/重复/分解)互不冲突、可叠加,zero-shot 跨域 SOTA——Terminal-Bench 86.5%、SWE-Bench 78.2%、机器人 87.4%。...
Read More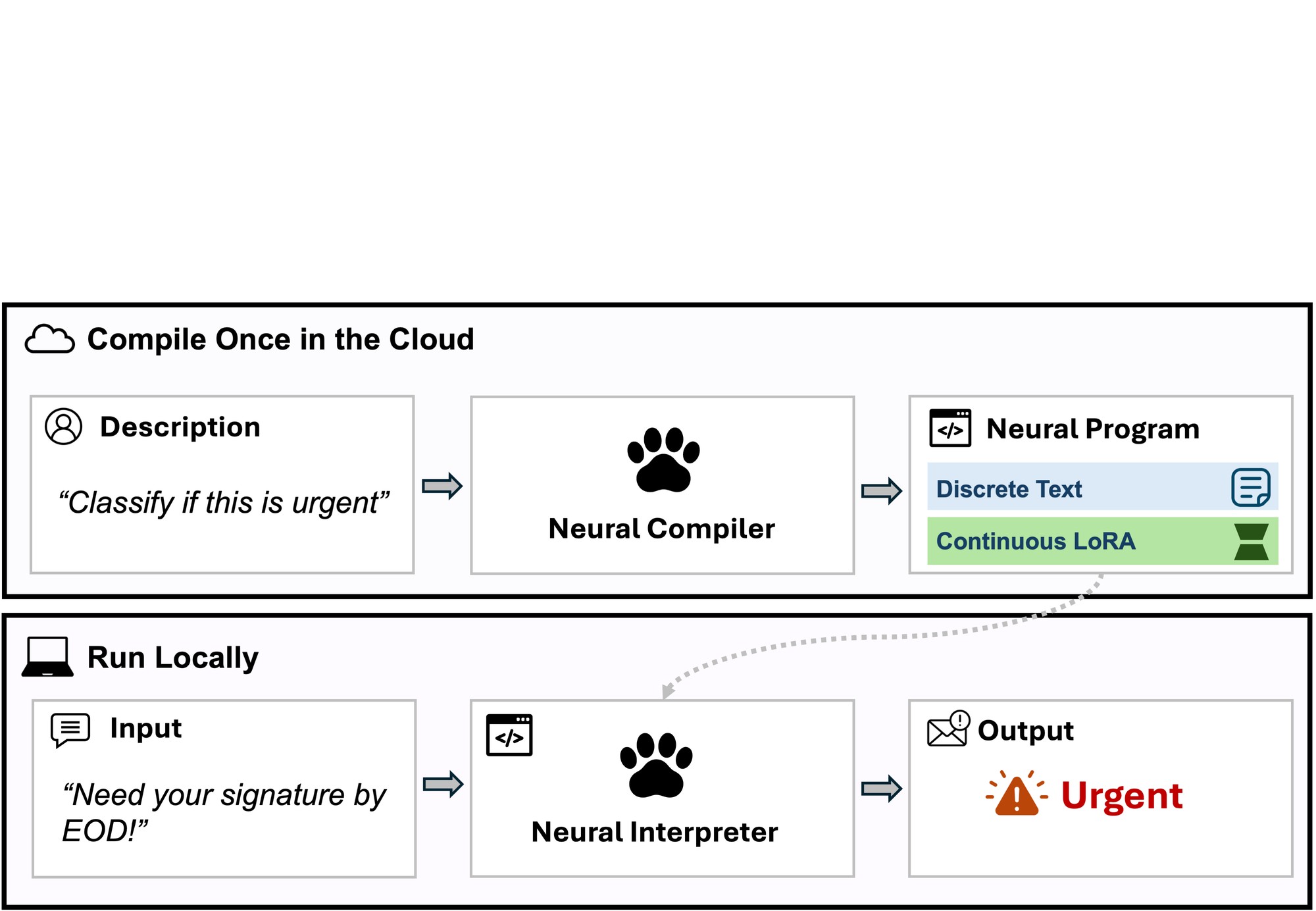
当权重变成代码:PAW 如何用 0.6B 模型打败 32B 大模型
把自然语言规格编译成 23MB 的 LoRA 适配器,0.6B 解释器本地运行。0.6B+PAW 精度超过 32B 直接调用,内存省 50 倍——权重即代码的新编程范式。...
Read MoreLLM的科研品味比人类窄得多
从分布层面测量LLM与人类在科研品味上的系统性差异:人类12%走桥接路径,LLM直接50-60%。不是不会做科研,是只会做一种口味——缝合。...
Read More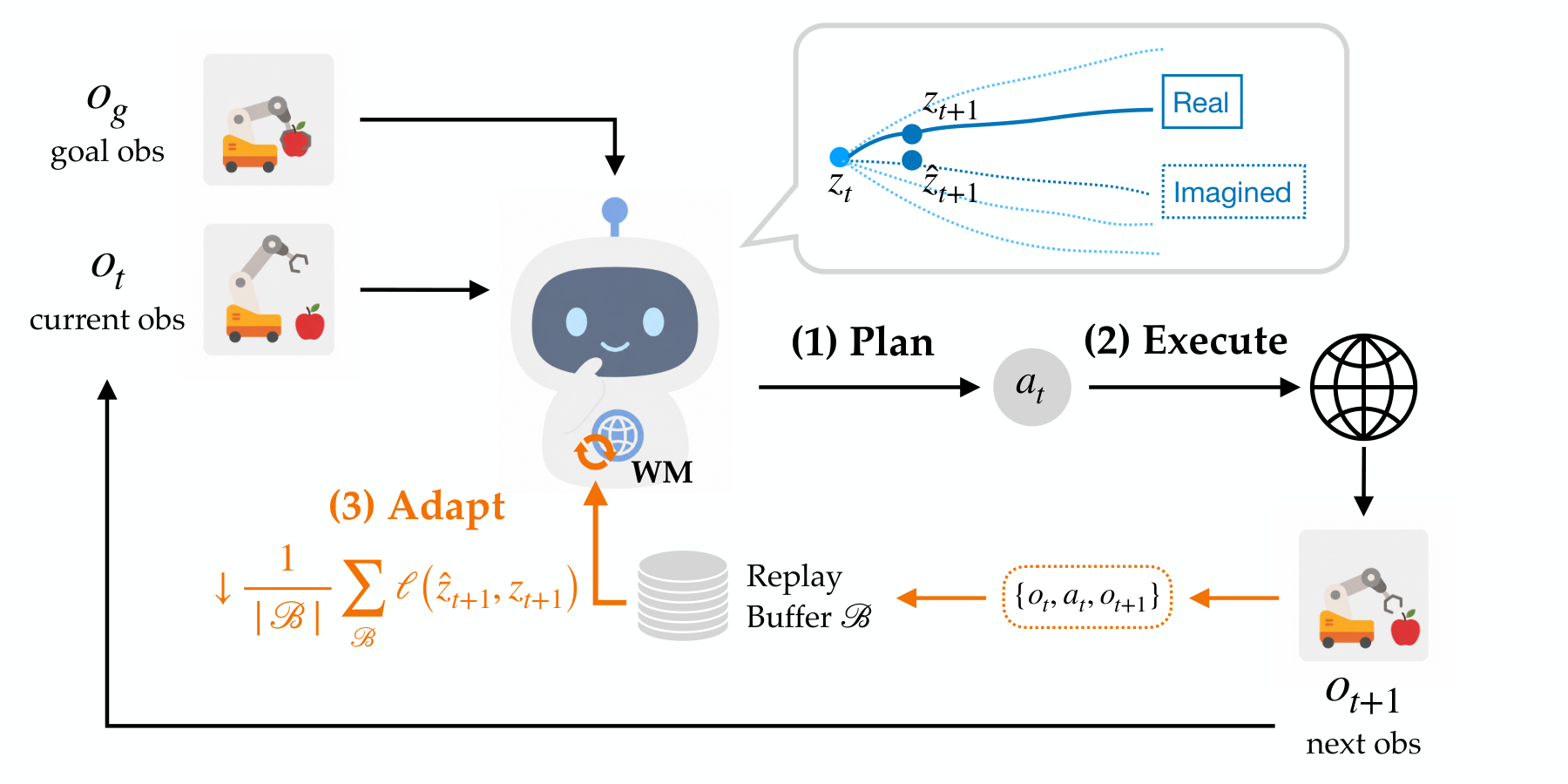
AdaJEPA:世界模型不该冻住,边用边学才是正道
一步梯度更新 predictor,每个 MPC step 仅多 0.01 秒,规划成功率翻倍。低数据 regime 下 1k 轨迹 + adaptation 碾压 16k 轨迹的冻结模型。...
Read More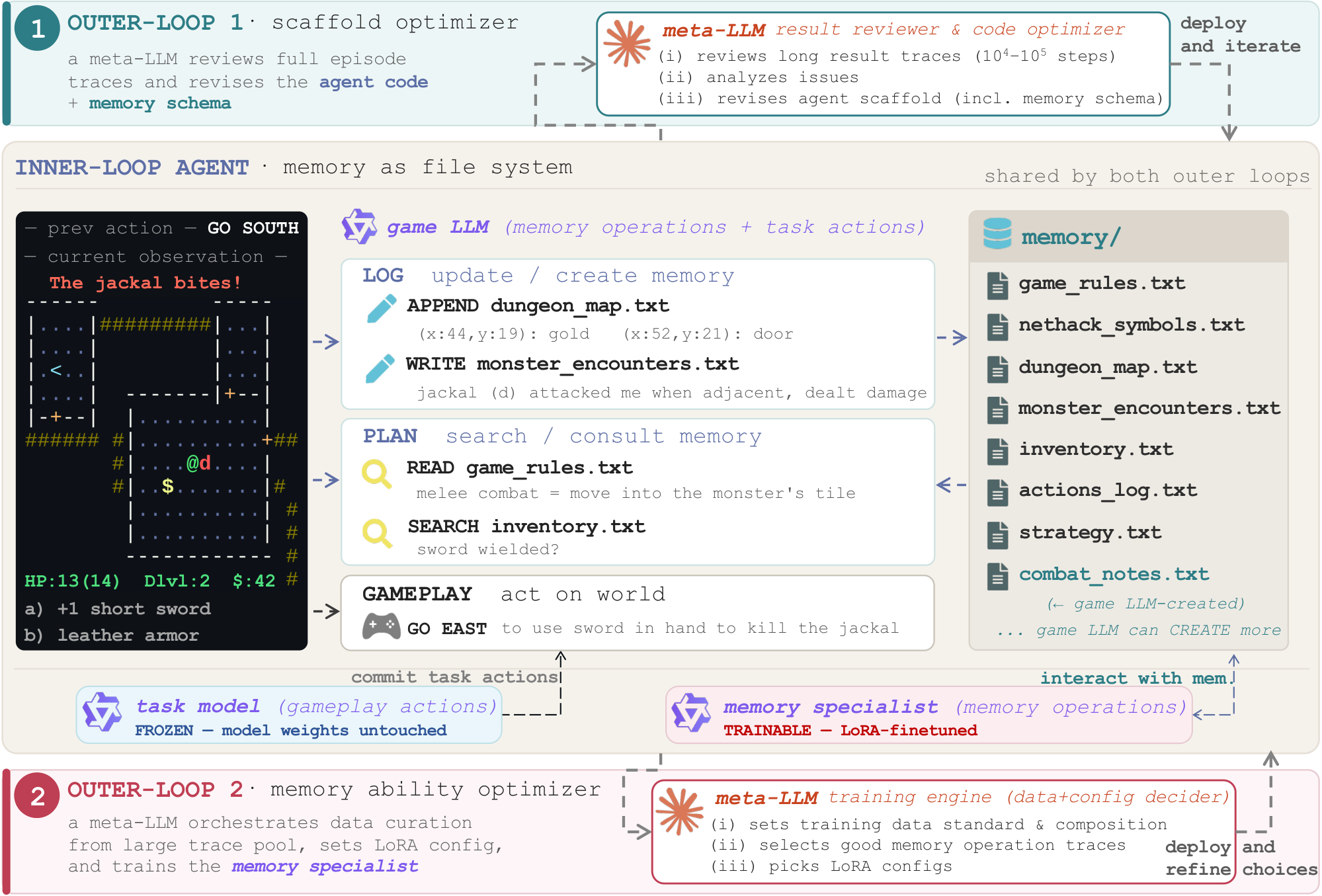
AutoMem:把记忆管理变成一种可训练的认知技能
Stanford 团队将元记忆认知能力搬到 LLM agent:文件系统操作提升为一等公民动作,meta-LLM 驱动的两个自动优化循环(结构迭代 + 熟练度训练)在长时任务上实现 2x–4x 性能提升,32B 模型达到 frontier 级别。...
Read More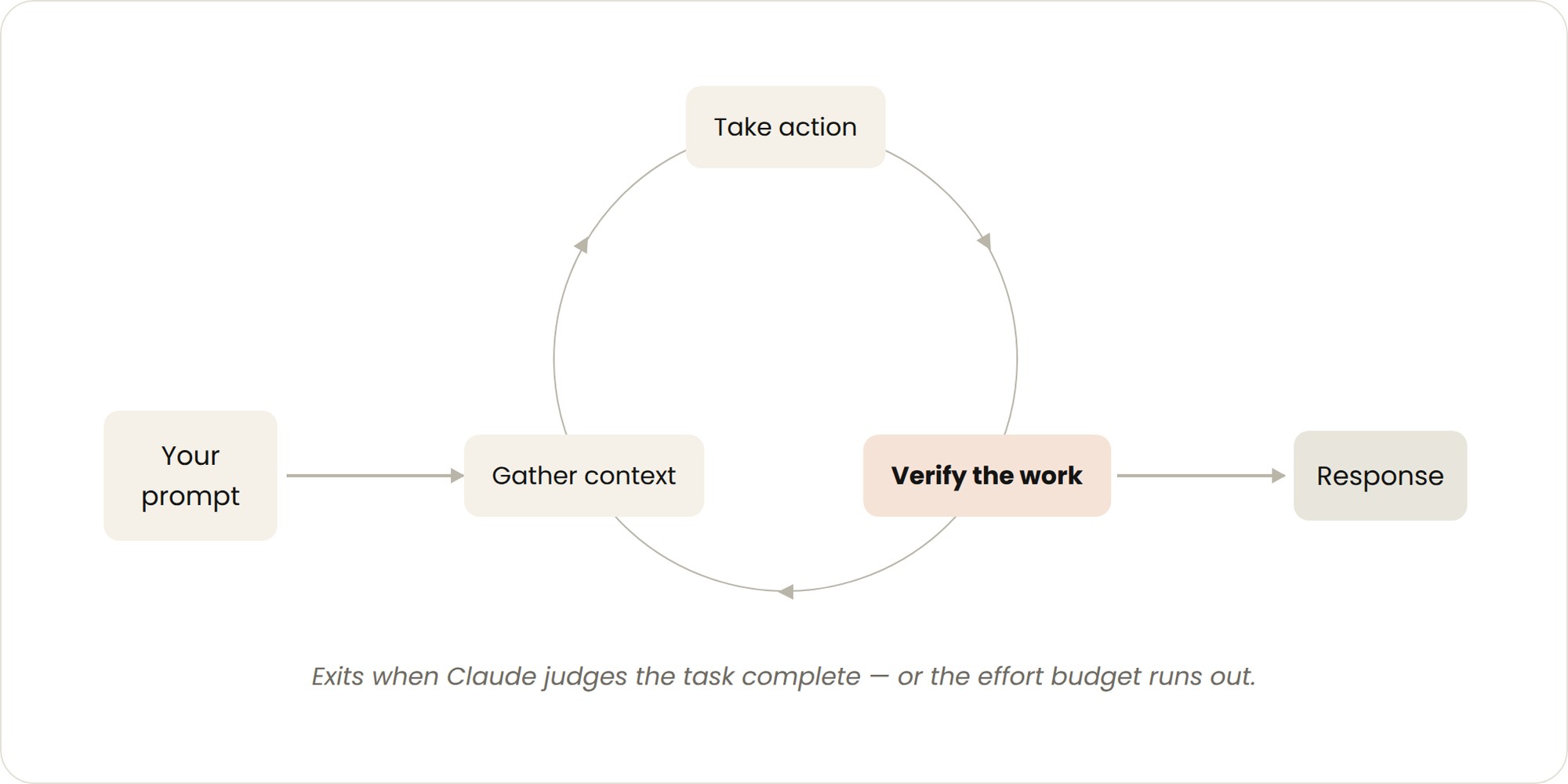
Claude Code Loops:四种循环模式,AI 编程从回合制到自主迭代
Anthropic 发布 Claude Code Loops,将 AI 编程助手从单次问答推进到自主循环执行。Turn-based / Goal-based / Time-based / Proactive 四种递进模式,覆盖人工协作到全自动化的一切场景。evaluator 模型防偷懒、advers...
Read More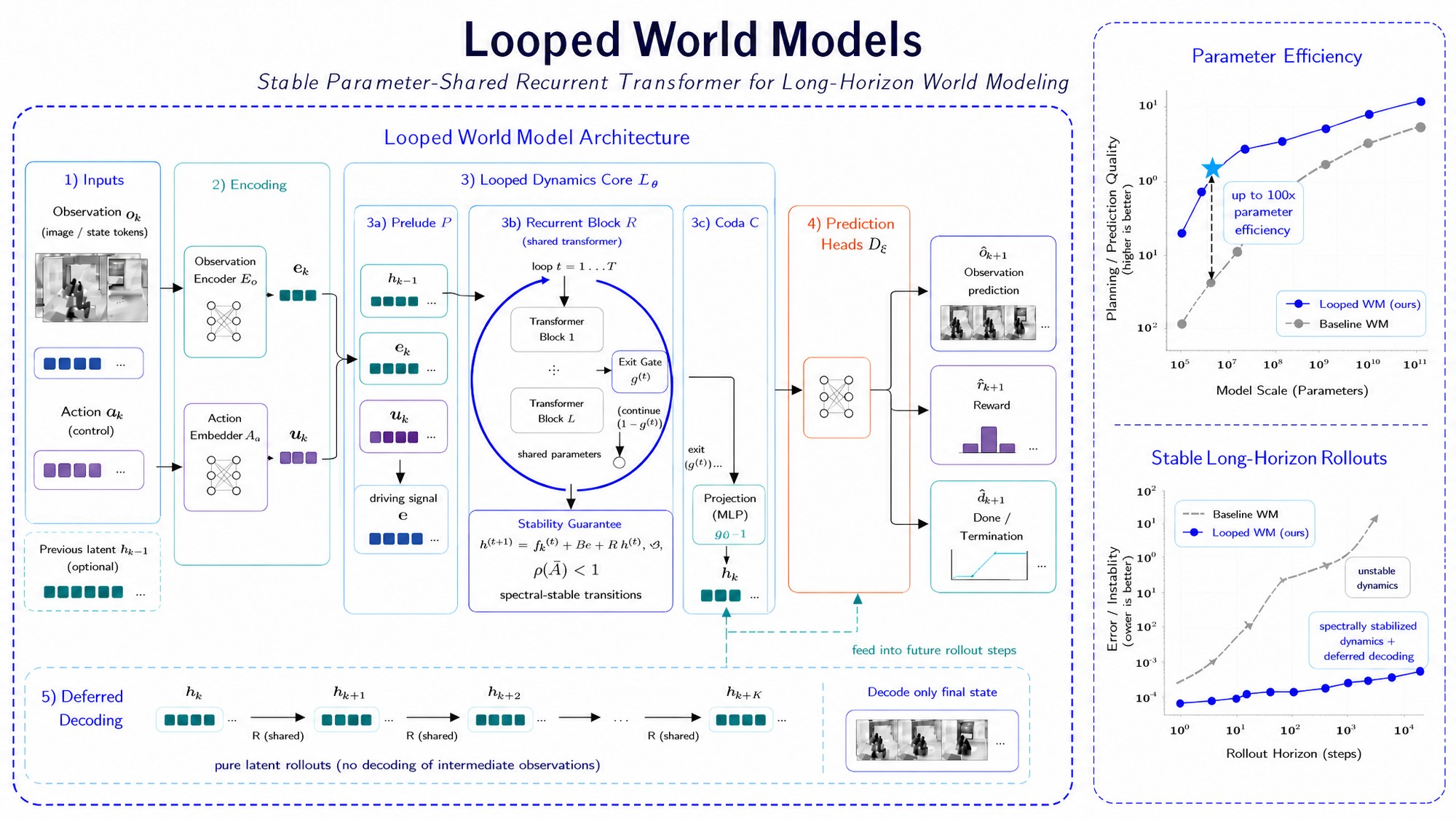
LoopWM:循环世界模型——迭代隐深度,世界模拟的第三条缩放轴
1B 参数的循环世界模型,参数共享 Transformer 块迭代精化隐状态,谱约束保证稳定。ScienceWorld 上超越 100x 大的 Claude Opus 4 Max 整整 21 个百分点。世界模型的第三缩放轴:迭代隐深度。...
Read More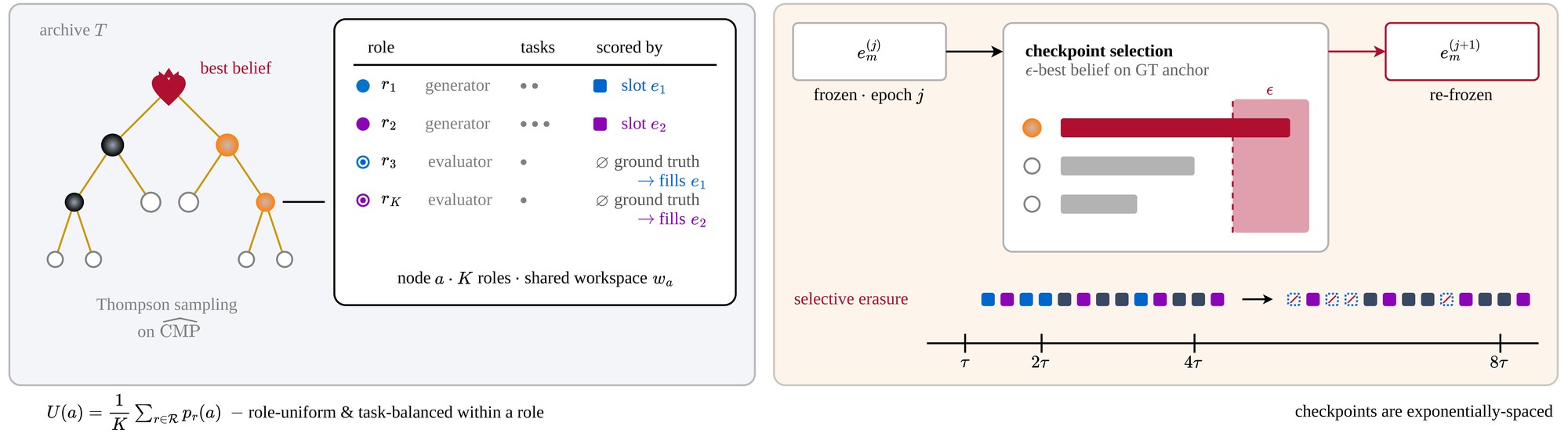
Autodata:让 AI Agent 当数据科学家,自己造高质量合成数据
四子 agent 架构(Challenger/Weak Solver/Strong Solver/Judge)迭代造题、调难度、验证质量。外循环元优化让 agent 越造越强。CS/法律/科学推理三领域全面优于传统 Self-Instruct。...
Read More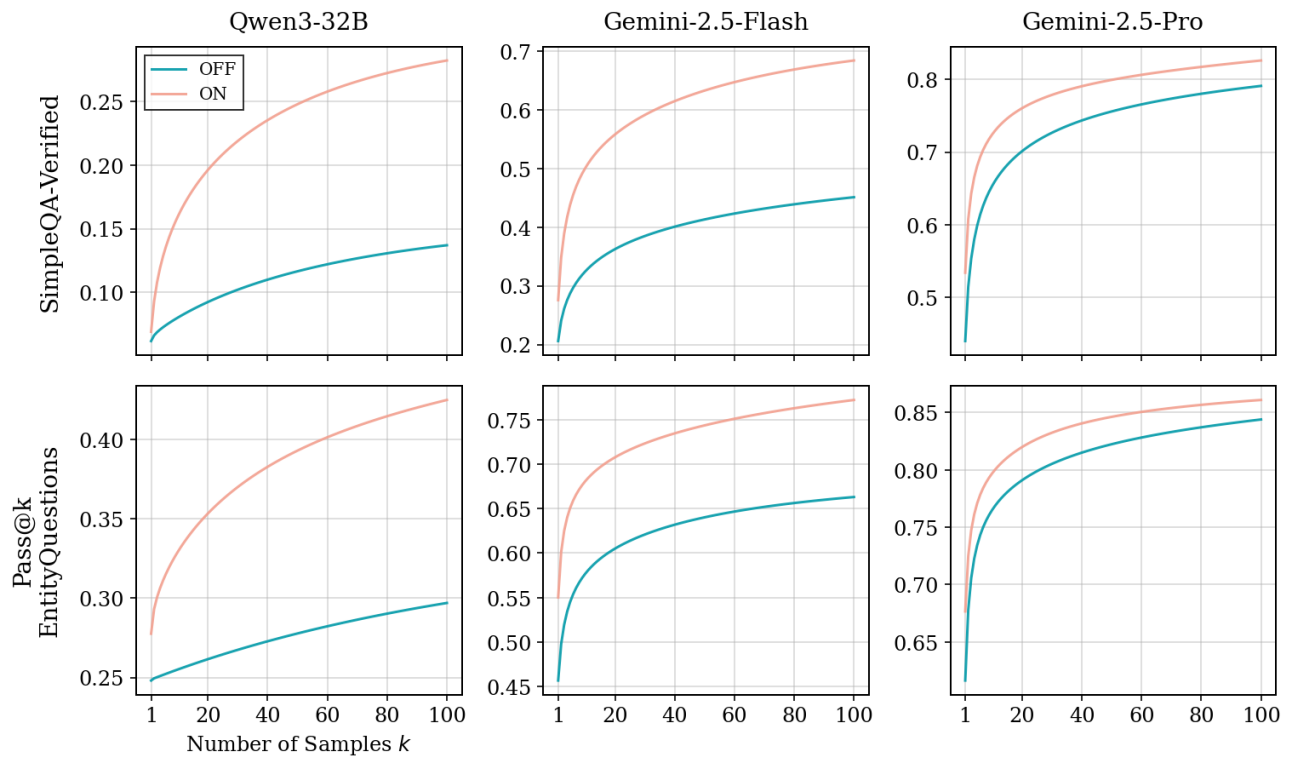
思考即回忆:推理如何解锁 LLM 的参数化知识
CoT 推理帮助简单事实回忆,不是因为分解了问题,而是两个互补机制:计算缓冲效应(额外 token 提供更多前向传播,无意义内容也有效)和事实启动效应(生成相关事实做语义热身,类似人类扩散激活)。中间步骤幻觉会显著拉低最终正确率。...
Read More用成功轨迹的访问分布学习过程奖励:让稀疏奖励 RL 真正跑起来
训练判别器区分成功/失败轨迹的 state-action 访问分布,用输出比率作为过程奖励。理论上保证不改变最优策略(Theorem 4.1),LIBERO-90 + 真实 WidowX 机械臂上约 5 倍加速。对抗式逆 RL 在稀疏奖励设定下的优雅变体。...
Read More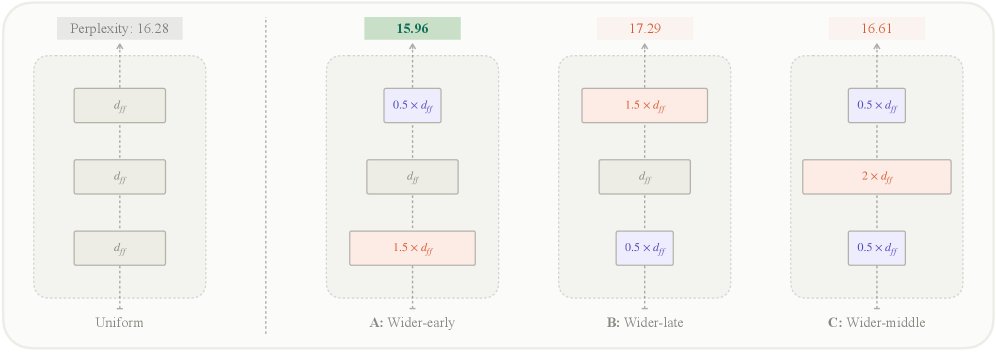
Tapered Language Models:MLP 宽度单调递减,免费的性能提升
让 MLP 中间层宽度沿深度 cosine 递减,总参数量和 FLOPs 完全不变。440M Transformer ppl 从 16.28 降到 14.44。跨四种架构(Transformer、Gated Attention、Hope-attention、Titans)、三种规模全部提升。层新颖度...
Read More禅与机器学习研究艺术
硅谷研究员 Jordan Mass 用禅宗公案串起 ML 研究底层心法:好结果大概率是 bug、别读太多论文、别追热点学底座、实验结果的平等心、Coding Agent 的理解外包陷阱。技术会变,但好奇心、偏执、对真相的敬畏不会过时。...
Read More
Spatial-TTT:用 Test-Time Training 给 MLLM 装上空间记忆
用 fast weights 做流式压缩的空间记忆,以线性复杂度处理任意长度空间视频流。混合 TTT 架构保护预训练知识,空间预测机制注入 3D 时空归纳偏置。2B 模型在 VSI-Bench 上超越 GPT-5 和 Gemini-3-Pro。...
Read More
Skill-MAS:把多 Agent 编排能力变成可进化的"元技能"
把 MAS 编排能力抽象为可进化的 Meta-Skill(prompt 级),解耦模型能力和经验积累。Multi-trajectory rollout + selective reflection 两步闭环进化。跨 LLM、跨任务迁移有效,四个 benchmark + 四个 LLM 全部最优。...
Read More
Looped World Models:把"深度"变成一个可调的旋钮
第一个把 looped transformer 用在 world model 上。参数共享 block 反复迭代隐状态,简单场景迭代 1 次,复杂碰撞迭代多次。谱约束保数值稳定,最高 100× 参数效率。开辟"迭代隐深度"这个全新 scaling 维度。...
Read MoreVariable-Width Transformers:不是所有层都该一样宽
系统研究 Transformer 层间宽度分配。× 形(两头宽中间窄)轮廓一致优于等宽 baseline:perplexity 低 ~3%,训练 FLOPs 省 22%,KV cache 省 15%。固定 residual slice 机制零参数开销。...
Read More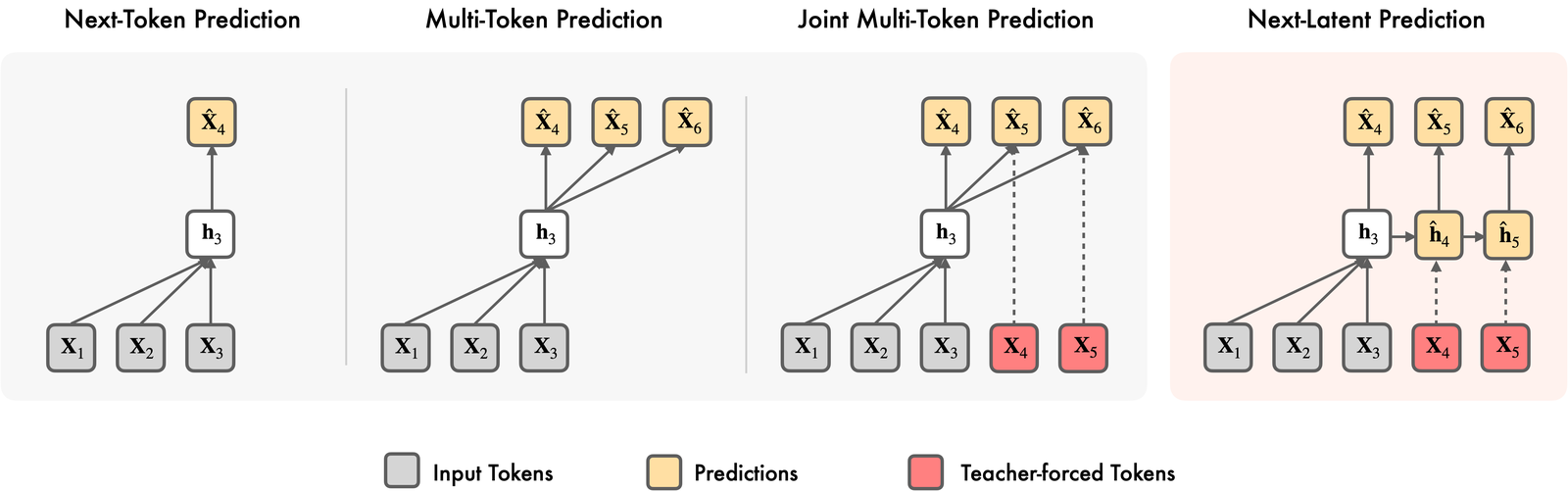
NextLat:让 Transformer 学会压缩世界
给 next-token prediction 加辅助目标——预测模型的下一个隐状态。理论上证明隐状态收敛到 belief states,推理速度 3.3× 且零额外开销。不改架构、不改推理流程,只改训练目标。...
Read More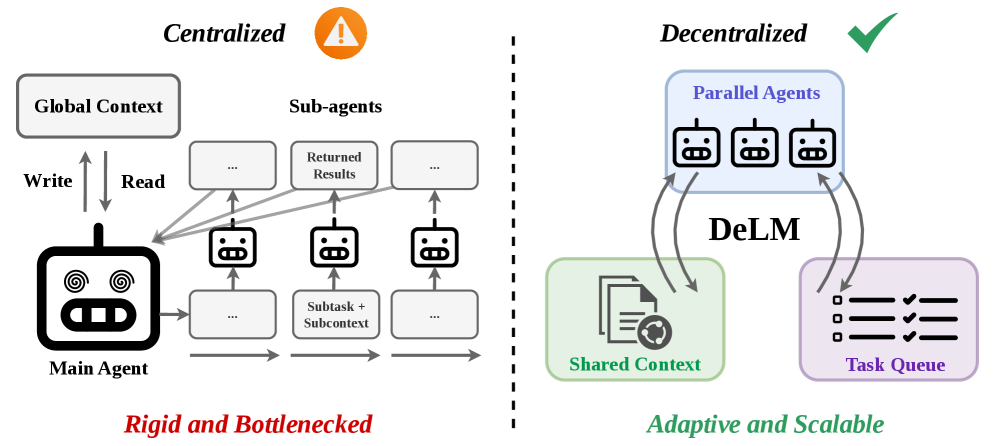
DeLM:用去中心化共享上下文打破多智能体协作瓶颈
用共享上下文 + 任务队列替代中央控制器,彻底去掉 scatter-gather 瓶颈。SWE-bench Verified 65.7%(+10.5pp),成本砍半。与 DecentMem 天然互补:一个去中心化协调,一个去中心化记忆。...
Read MoreDecentMem:去中心化记忆拯救多智能体多样性
首个去中心化 MAS 记忆框架。每个 agent 维护私有双池记忆(利用池 + 探索池),LLM-as-a-judge 在线动态加权。理论证明全局可达性 + O(log T) 累积遗憾。15 组实验 14 组最佳,比最强中心化基线高 8.6%,token 减少最多 49%。协调随机性越高,去中心化优...
Read MoreLoop Engineering:别再 Prompt Agent 了,去设计循环
基于 Addy Osmani 文章:五个构件(自动化、Worktree、Skill、Connector、Sub-agent)加一块外部记忆,构成完整的 agent 自动化循环。杠杆点从 prompt 能力移到了系统设计,但系统产出的上限仍然是你对工作的理解深度。...
Read MoreFrom AGI to ASI:DeepMind 首次系统性描绘后 AGI 时代的技术路线图
57 页报告,以 Legg-Hutter 智能量表为理论基础,提出 AGI→ASI 四条路径:scaling、范式转移、递归自改进、多智能体涌现。系统列举数字智能结构性优势与摩擦力瓶颈。核心判断:AI 进步不太可能精确停滞在人类水平,多智能体架构可能是最被低估的 ASI 路径。...
Read MoreLLM 自改进全景:从数据飞轮到自我修改代码的完整生命期
113 页综述,提出 GRO(生成-奖励-优化)统一框架覆盖从 STaR 到 Gödel Machine 的全谱系。五阶段闭环(数据获取→筛选→优化→推理精炼→自主评估)+ 六种结构性失败模式(数据自噬、reward hacking 等)。核心判断:自改进的未来在系统层面的闭环设计,而非模型层面的技...
Read More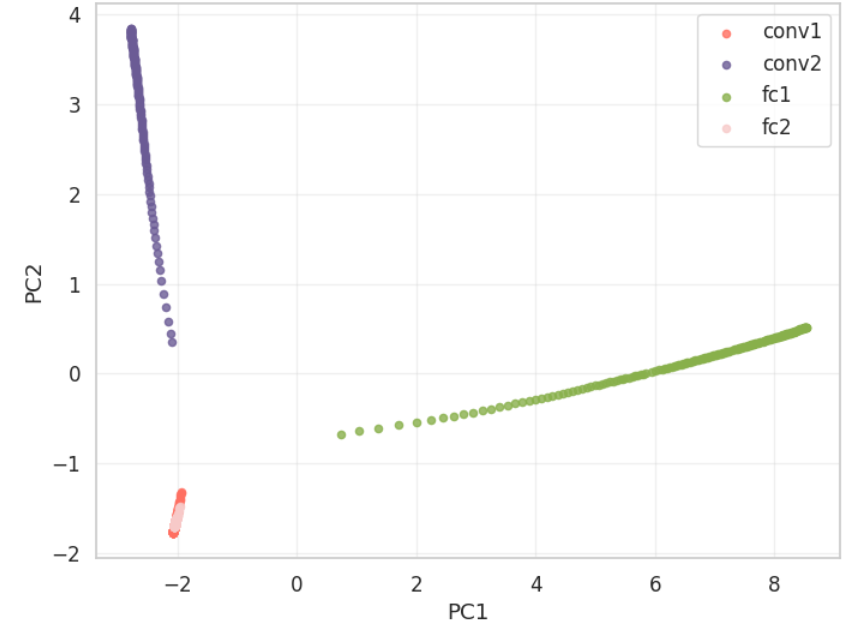
Mapping Networks:用低维潜变量替代高维权重空间
权重流形假说 + 映射定理严格证明:仅训练一个千维潜向量即可生成完整网络权重,实现 200-500× 参数压缩。四项 Mapping Loss 分别对应定理假设,消融验证缺一不可。微调场景落地点最快——1024 参数适配 ResNet50 超越 17M 全参数微调。...
Read MoreLEAP:用 Agentic 框架让通用大模型在形式化数学上达到 SOTA
AND-OR DAG 证明图架构,把通用 LLM 在形式化定理证明上的解决率从不到 10% 提升到 70%。Putnam 2025 全对(12/12),超越金牌级 IMO 专用系统 Aristotle。核心设计:引理记忆化 + 前瞻性规划 + LLM Reviewer 作搜索过滤器。...
Read More最后一篇人类写的论文:Agent-Native Research Artifact
学术论文把分支迭代的探索过程压缩成线性叙事,丢掉大量沿途发现。ARA 协议用四层机器可执行研究包替代叙事论文,理解准确率 72.4% → 93.7%。最深刻的发现:结构化知识对弱 Agent 是助力,对强 Agent 可能变成约束。...
Read More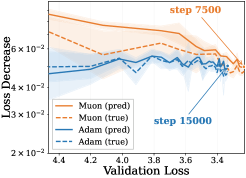
Why Muon Outperforms Adam: A Curvature Perspective
Muon 比 Adam 快 2 倍的原因:不是梯度对齐更好,而是谱归一化更新方向有更低的 Normalized Directional Sharpness (NDS),每步曲率代价更小。数据越不平衡、训练越到后期,优势越明显。...
Read More一个工程师的 Agentic Engineering 全部家底
Matt Van Horn 从"高中后再没交付过有价值的东西"到多个万 star 项目贡献者,靠的不是更努力写代码,而是彻底改变和计算资源的关系。Plan First 翻转 80/20、双层规划破解模型偷懒、多 Tab 并行人变调度员——一整套正在形成的 Agentic 工程方法论。...
Read MoreDepth-Attention:让 Transformer 在深度维度上也学会"选择性注意力"
自注意力在序列维度自由选择信息,但在深度维度只是残差累加。Depth-Attention 在注意力模块内部增加"沿深度方向的注意力",让每层从前面的层选择性复用 value——零参数、零额外 KV cache、不到 0.01% 额外 FLOPs,1.5B/3B Qwen3 风格解码器全面最优。...
Read MoreAnthropic 用 Claude 做自助数据分析的完整工程体系
裸 Claude 回答数据分析问题准确率仅 21%,加上 skill 稳定 95%+,不维护一个月掉回 65%。四层架构(Data Foundations → Sources of Truth → Skills → Validation),精加工知识而非原始检索,LLM 自动生成元数据定义"净效果为...
Read More当 AI 构建自身——Anthropic 递归自我改进进展报告
Anthropic 首次披露内部数据:80%+ 代码由 Claude 编写,工程师代码产出是 2024 年的 8 倍,Claude 单次提交 800+ 修复将 API 错误降低 1000 倍。反馈循环已启动——每次 Claude 升级都加速下一个版本的构建。研究判断力是通向完整递归自我改进的关键鸿沟...
Read More动态短卷积:给 Transformer 加一个"会看情况的"局部感受野
将静态短卷积替换为输入依赖的动态卷积,150M-2B 模型上 1.33-1.60× 计算优势,端到端训练仅 +8% 开销。泛化至 MoE、Mamba-2、Gated DeltaNet。思路简单、收益显著——几乎无脑可加的架构改进。...
Read MoreAI 攻击者画像:832 个恶意账户揭示的三个关键趋势
Anthropic 审查 832 个恶意账户,映射到 MITRE ATT&CK 框架。三大发现:攻击重心从钓鱼向后渗透转移、传统威胁评估体系因 AI 而失效、编排架构成为高危攻击者唯一持久区分信号。...
Read More为什么大模型能学会小模型学不会的东西?——梯度干扰与稀有任务的留存
大模型不是"更聪明"——而是参数多到高频任务的梯度变得极微弱,不再覆盖稀有任务缓慢积累的特征。用 OLMo 4M–4B 实验验证:1B 模型对非任务 token 的梯度干扰仅 7.58×10⁻⁵,20M 模型高达 0.10。数据中心化:提高数据频率可能比盲目扩大模型更有效。...
Read Moreδ-mem:用 8×8 矩阵给冻结 LLM 加上在线记忆
在冻结 LLM 旁维护 8×8 在线关联记忆矩阵,通过 delta-rule 持续更新,读取向量直接注入 attention 生成低秩修正。MemoryAgentBench +31%,移除全部上下文后仅凭 64 元素矩阵仍能恢复关键推理链。...
Read More
Video-o3:让视频理解模型学会"主动找线索"
Video-o3 给视频 MLLM 装上"主动寻线索"能力——迭代调用 VideoCrop 精查关键片段,攒够证据再下结论。7B 模型在 MLVU 72.1%、Video-Holmes 46.5% 刷 SOTA。...
Read MoreOryx:在序列维度上自由切换 Attention 和线性循环
序列轴混合:tied K/V 投影共享 90%+ 参数,一套表示同时更新 KV cache 和 RNN state,序列内动态切换 attention 和 linear RNN。linear prefill + attention generation 即追平 Transformer 检索,算力省得...
Read MoreLatent Prediction:LLM 的下一个范式?把 Token Prediction 换成潜变量预测
Meta 提出将 LLM 预训练从离散 token prediction 换成连续潜变量预测——autoencoder 先压缩 token 到 latent,模型预测 latent 向量而非 next token。推理速度提升 2.7×,质量持平甚至超越,语义等价性大幅增强。...
Read MoreSIA:同时拧两颗螺丝的自改进 AI
第一个在同一个闭环中同时更新 scaffold 和模型权重的系统。Feedback-Agent 运行时动态选择 RL 算法,三个跨域实验一致证明 harness 与权重更新增益不互相饱和。...
Read More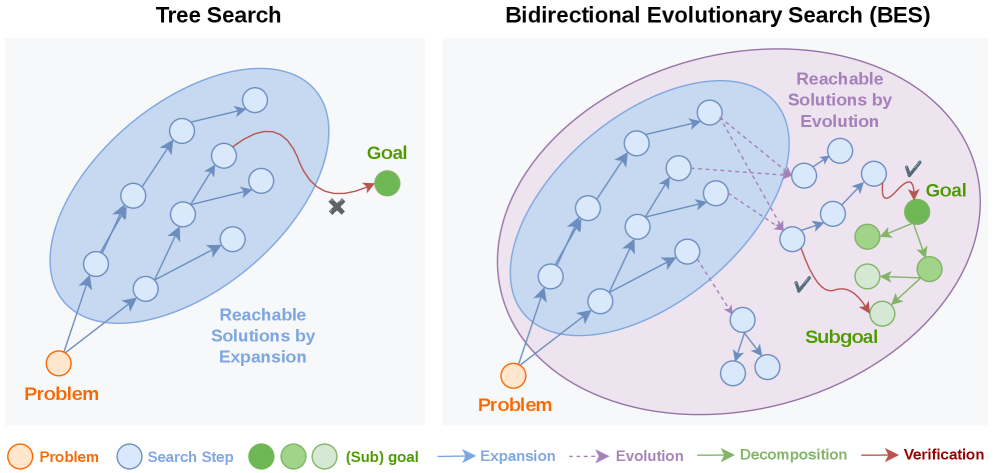
BES:给大模型一杆秤,它就能自己改代码
DeepMind 的自改进代码优化器:给定一个评分函数,模型在三个阶段(种群采样→自我评估→自我优化)中迭代生成、评分、改进代码,无需外部 solver。3× 计算量即可达到 2× 最终性能,且跨模型泛化。...
Read More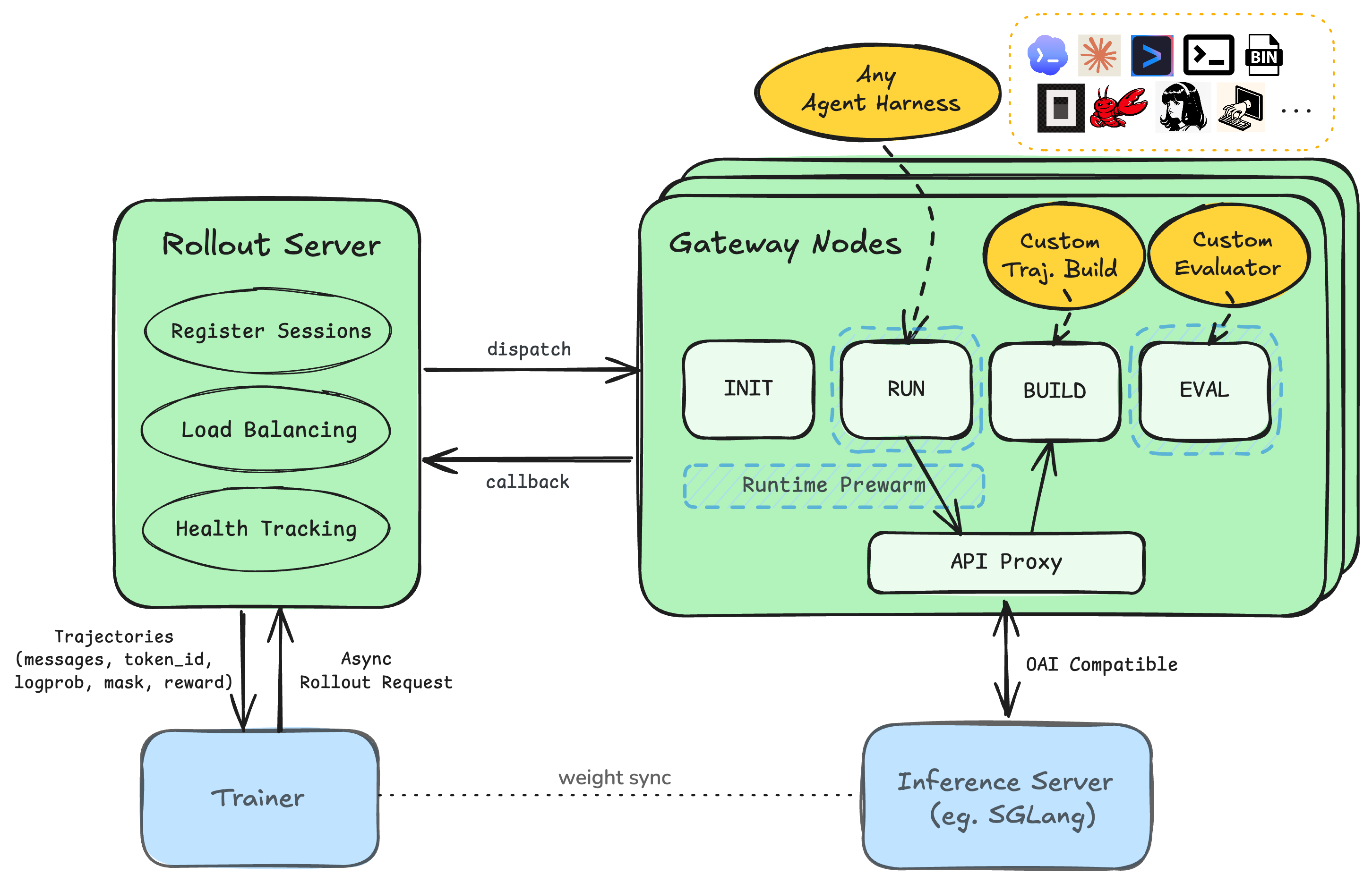
Polar:把任意 Agent 框架变成 RL 环境的黑盒方案
NVIDIA NeMo 团队的 rollout 框架:在 LLM API 边界架代理捕获 token 级交互,把任意 agent harness 当黑盒做 scalable RL。Qwen3.5-4B + GRPO 在 Codex harness 上 SWE-Bench Verified 从 3.8...
Read More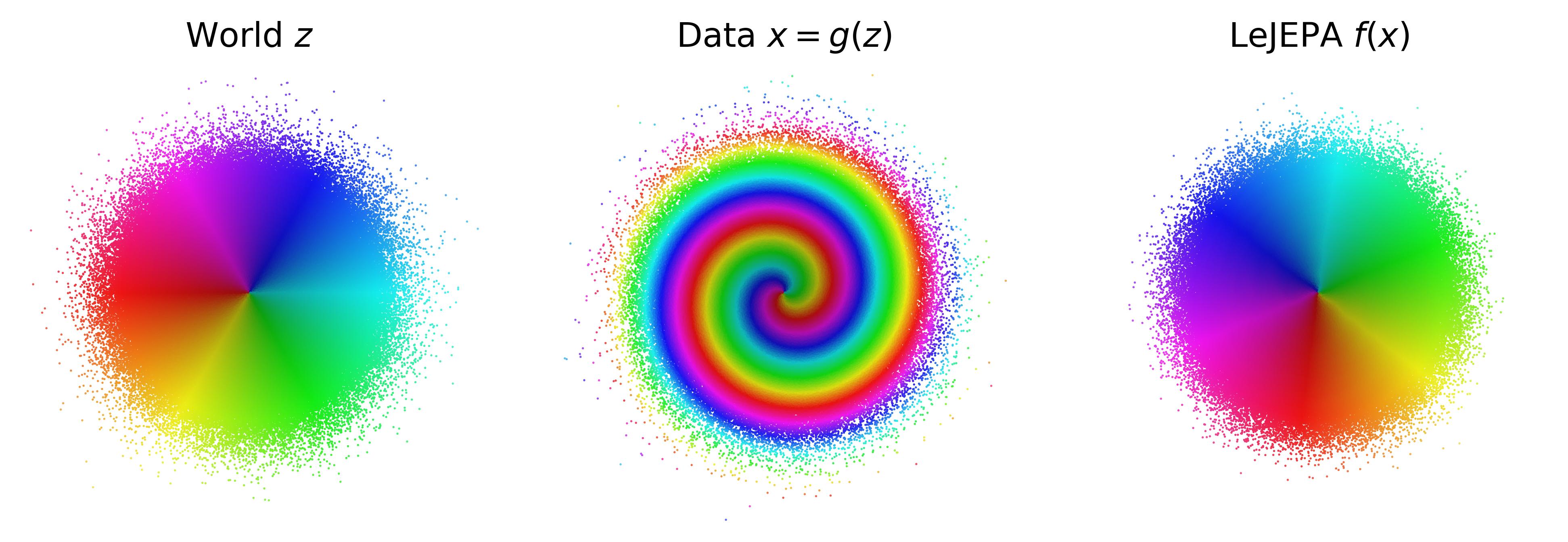
LeJEPA 何时学到 World Model?JEPAs 的首个线性可辨识性理论
LeCun 团队用 Hermite 多项式谱分解证明:LeJEPA 在高斯潜变量下必然线性恢复 World Model(h(z)=Qz),且高斯是唯一满足此条件的分布。反转了经典 ICA 的结论——Gaussian 的旋转不变性从 bug 变成 feature。四个定理递进,Lean 4 形式化验证...
Read More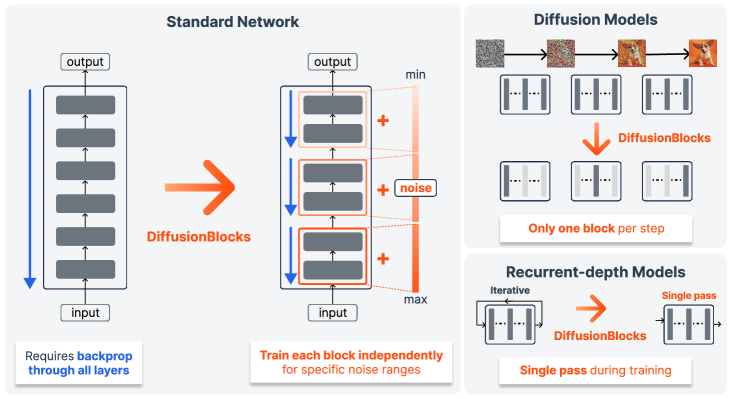
DiffusionBlocks:残差连接就是扩散步,反向传播从此可选
残差连接天然等价于扩散去噪的欧拉离散化——利用这一等价关系,把网络拆成独立块训练,显存降 B 倍,效果和端到端训练几乎一样。五种架构验证通过,包括非扩散原生的自回归模型。...
Read More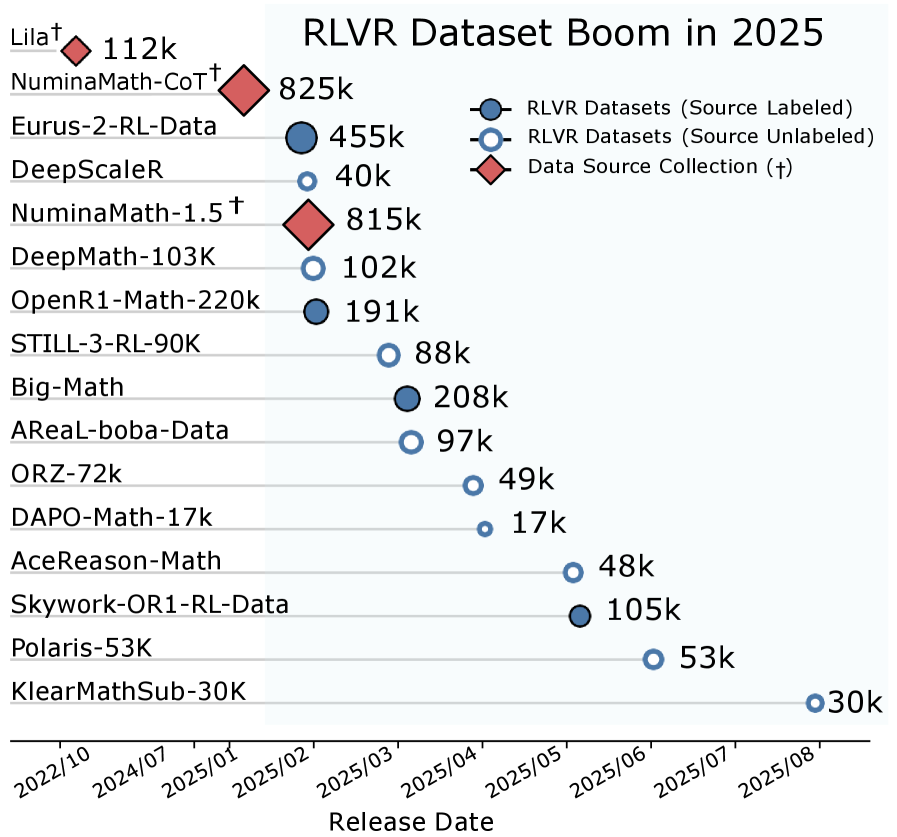
RLVR 数据集的家谱:ATLAS 追踪 145 万条数据回到 20 个原子源头
给 RLVR 数据集做家谱:1.45M 条训练数据 90%+ 来自 20 个原子源,3.6 万条 benchmark 泄露。提出 SCA 源级归因和 Q 质量评分,用洞察打磨出 DAPO++ 数据集,两个规模上全面第一。...
Read More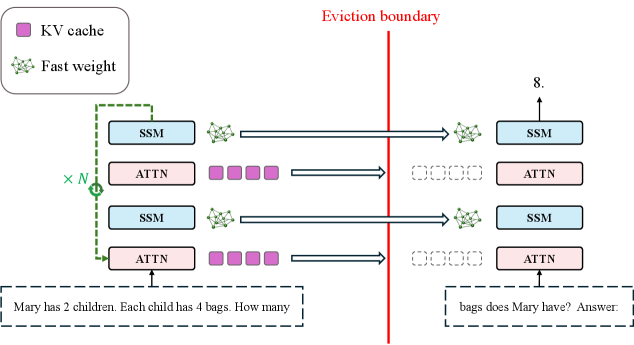
Language Models Need Sleep:让模型睡一觉再做推理
SSM-Attention 混合模型在深度推理上失败的原因不是记忆容量不足,而是巩固已驱逐上下文的计算量不够。解决方案:让模型在清除 KV cache 之前用循环前向传播反复精炼快速权重,推理延迟不变,睡得越久推理越深。...
Read MoreProject Glasswing 首月战报:AI 漏洞挖掘速度已超越人类修补速度
Anthropic 用 Claude Mythos Preview 联合 50 家合作伙伴,一个月发现超过 10,000 个高危漏洞。网络安全进步的瓶颈已从"发现"变为"修补"——传统 90 天披露窗口和志愿者驱动的补丁流程已不够用。...
Read More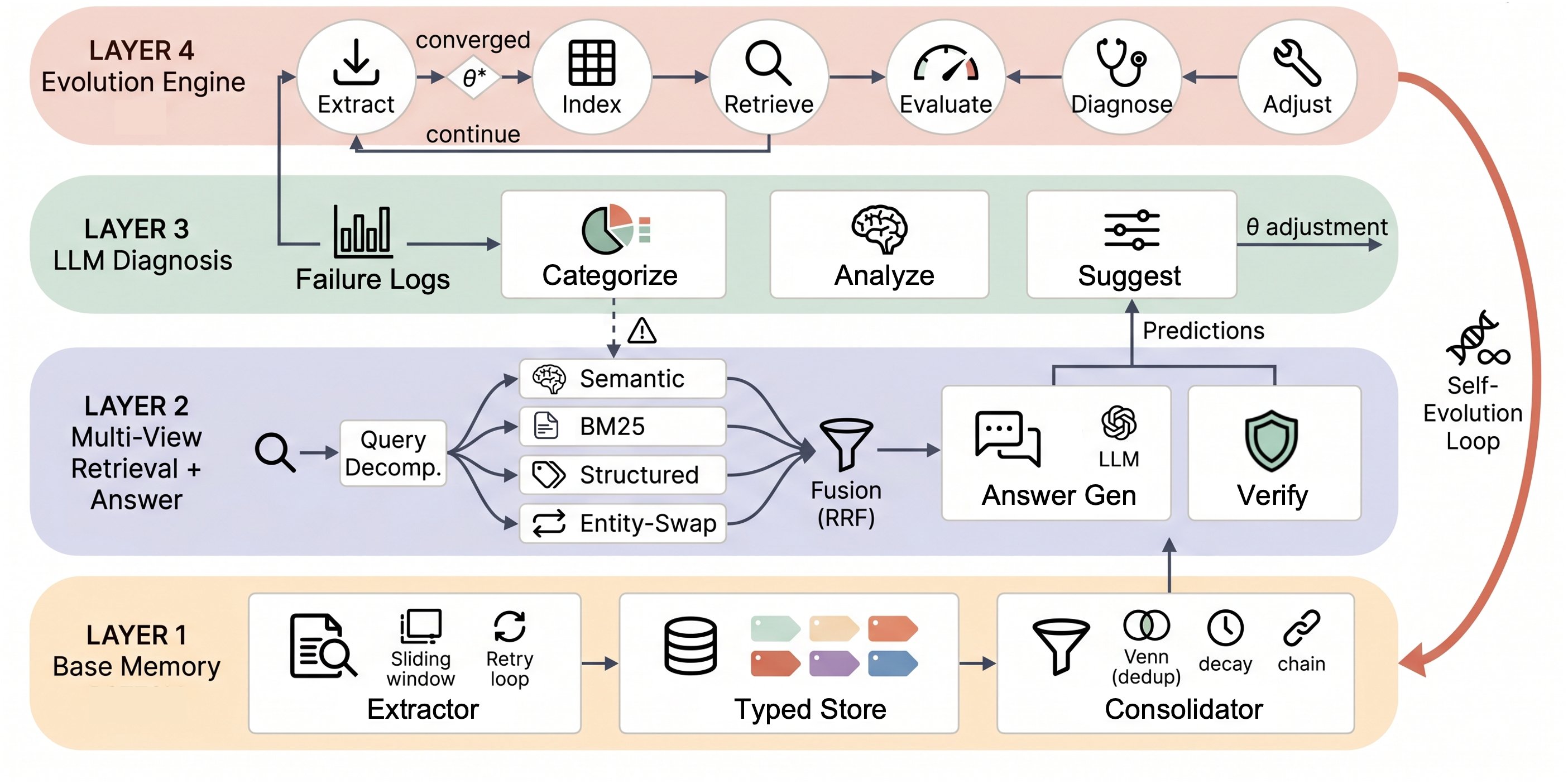
EvolveMem:让记忆系统的"检索引擎"自己进化
检索基础设施不该是静态的。把 BM25 权重、融合模式、上下文预算等十几个旋钮暴露为动作空间,LLM 读失败日志→诊断根因→提案调参→守卫回退的四步循环自动进化,从 F1 30.5% 七轮跑到 54.3%。...
Read More
AutoResearchClaw:让AI科研系统学会从失败中爬起来
五大机制(多Agent辩论、Pivot/Refine自修复、可验证结果报告、七档人机协作、跨Run进化)驱动的23阶段自主科研流水线。ARC-Bench上比AI Scientist v2高54.7%。...
Read More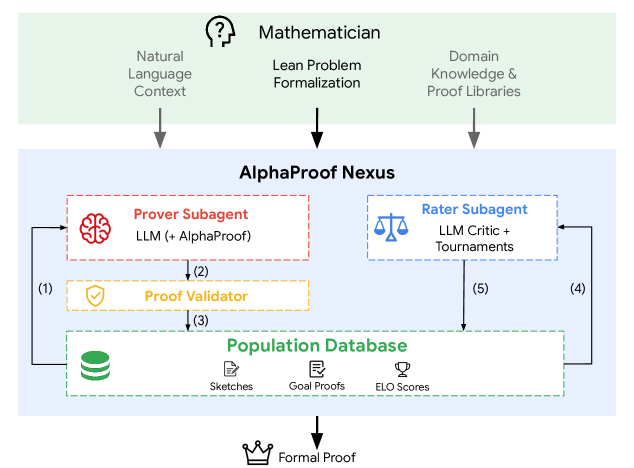
AlphaProof Nexus:AI 自动解决 9 个 Erdős 开放问题
LLM + Lean 编译器验证的 agentic loop 自动解决 9/353 Erdős 问题(含 56 年悬而未决难题)和 44 个 OEIS 猜想。最意外发现:最基础的 LLM+编译器循环就解决了全部成功案例,进化搜索反是锦上添花。...
Read More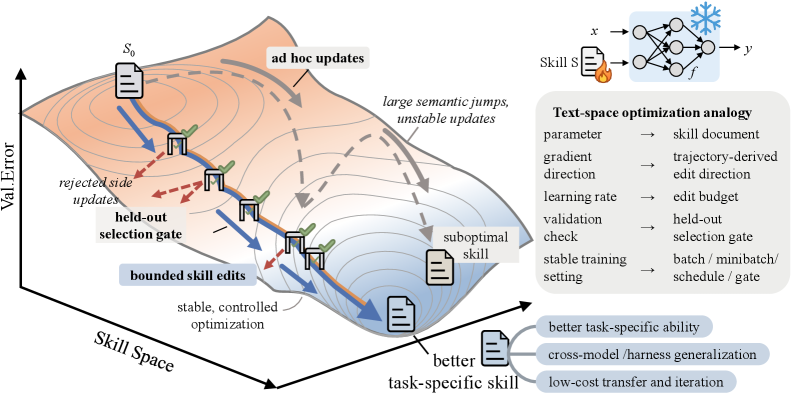
SkillOpt:把 Agent Skill 当成可训练的外部权重来优化
把 skill 文档当成 frozen agent 的外部权重,用训练的纪律来优化。52/52 全胜,skill 可跨模型跨环境迁移。...
Read More强老师不是必需品?LLM 预训练蒸馏的常识颠覆
知识蒸馏的黄金法则被推翻:弱老师也能教出好学生,强老师反而可能让蒸馏收益饱和甚至逆转。蒸馏的真正价值在泛化而非拟合。...
Read More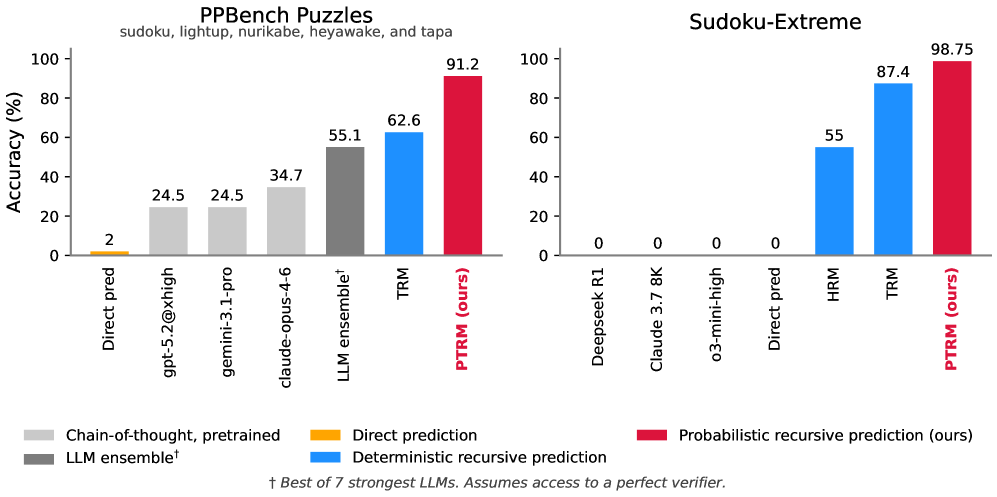
PTRM:7M 参数干翻 Claude-4,噪声解锁推理潜能
给递归推理模型加噪声、跑 K 条并行轨迹、用 Q 头选最优——不重训练、不增数据,7M 参数成本 $0.001,PPBench 准确率 91.2%(Claude Opus 4 仅 34.7%)。推理瓶颈在探索能力,不在模型容量。...
Read MoreGRAM:生成式递归推理,让神经网络学会"发散思维"
将递归推理从确定性变成概率性:高层随机探索 + 低层确定性精炼,支持宽度式推理扩展。Sudoku 97%、N-Queens 覆盖率 90.3%,20 条并行轨迹超越所有确定性模型 320 步迭代。...
Read MoreHRM-Text:40B token + $1500 训练出打平 2-7B 的 1B 模型
分层递归架构替代标准 Transformer,配合 task-completion 目标和 PrefixLM attention,40B token 从零训练 1B 模型,计算效率比 Llama/Qwen/Gemma 高 96-432 倍。$1,500 预算让任何实验室都能做预训练研究。...
Read More
用一台树莓派养两只 AI:我跑了三个多月的"家庭 AI 实验室"
600元树莓派 + 开源 nanobot,挂两个飞书AI助手(熊大&熊二),三个月自动出19期论文播客、近百篇论文解读、A股日报、美股模拟交易——每月电费1块8,API费用50块。一套普通人也能复制的7×24小时AI方案。...
Read MoreRAEv2:用预训练视觉编码器替代 VAE 的改进基线
三个简洁改进——多层特征聚合、保留 REPA、REPA head 免费做 guidance——实现比原版 RAE 快 10 倍收敛,80 epoch 达到 gFID 1.06,并在文生图和导航世界模型上一致验证有效。...
Read MoreMeMo:把记忆本身变成一个模型
用独立小模型当「记忆」,主模型完全不动参数。训练时消化语料,推理时多轮对话提问——RAG、微调、latent memory 之外的第四条路。...
Read More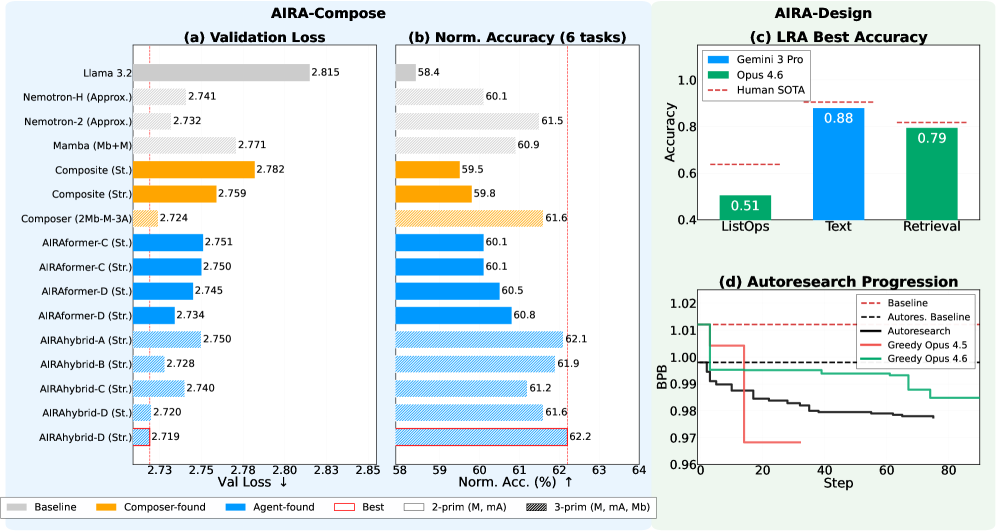
AI Agent 自动设计神经网络架构:AIRA-Compose 和 AIRA-Design
用 AI Agent 自动完成神经网络架构搜索。AIRA-Compose 通过组合现有模块进行设计,AIRA-Design 则从零开始构造全新架构——无需人工设计经验,端到端自动化。...
Read MoreOPD 为什么比 RL 快?"预见性"是答案
Opinion-Driven Policy Distillation 提出了一种比传统 RL 更高效的方法论。核心洞察是"预见性"——Agent 能够预判决策后果,从而跳过大量试错。...
Read MoreClaude Code 101 系列教程 · 9 课从入门到实战
来自 Claude 官方频道的完整教程系列:从安装到 MCP 集成、Hooks 钩子,覆盖 Agentic Loop、CLAUDE.md、Explore→Plan→Code→Commit 工作流、上下文管理等核心概念。...
Read More有用的记忆,在 LLM 持续更新中变得有缺陷
探索 LLM 持续更新中一个反直觉现象:即使是正确的、有用的记忆,在模型更新后也可能变得不可靠。对持续学习系统的记忆管理提出警示。...
Read More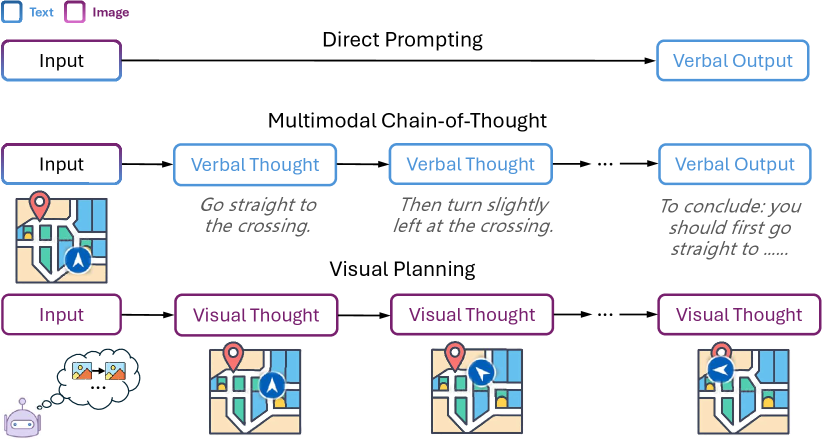
Visual Planning:只用图像思考,不用语言推理
挑战"语言是推理必需载体"的假设,证明纯视觉规划可以完成复杂推理任务,且在某些场景下优于语言链式推理。...
Read More